2025
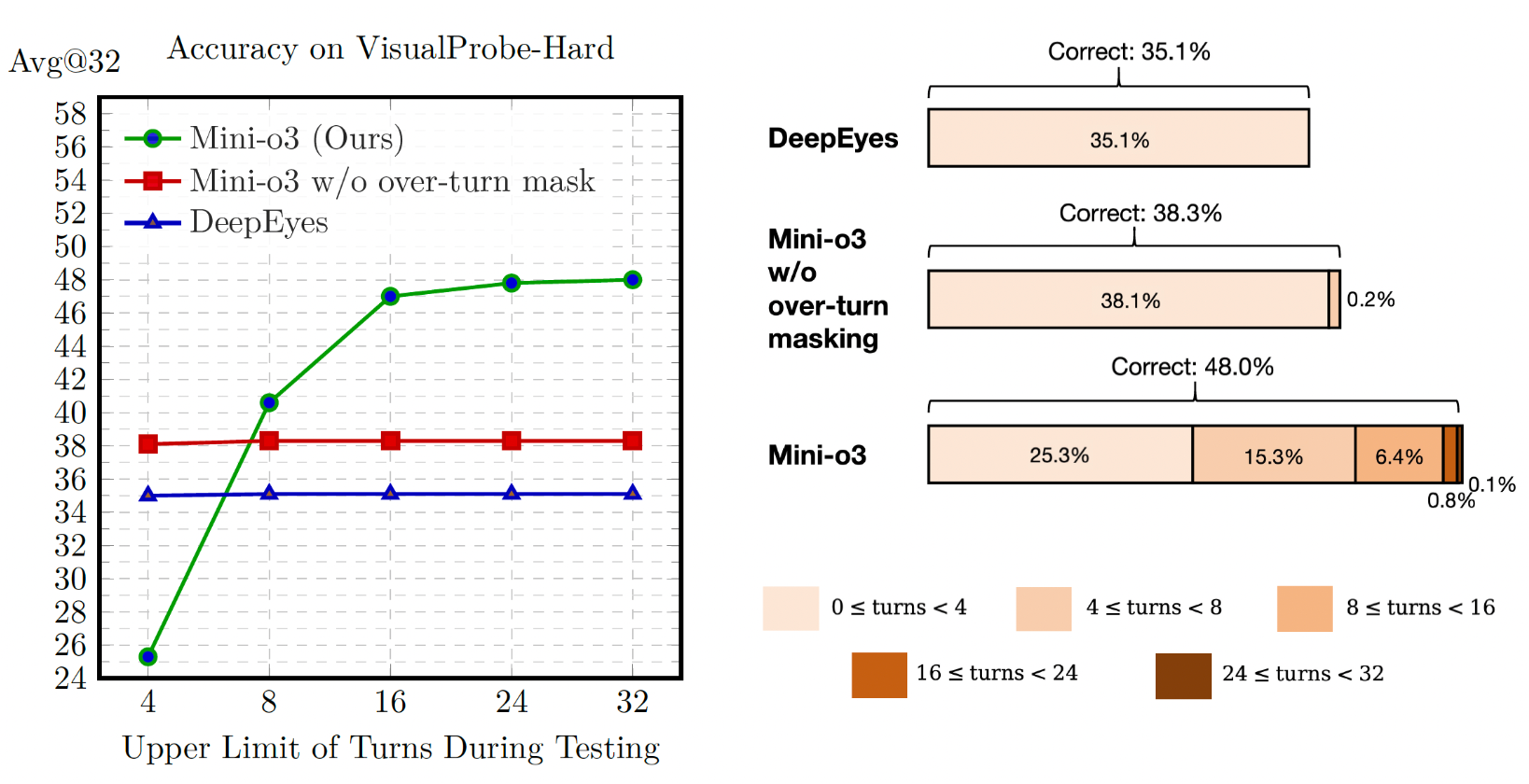
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Xin Lai*, Junyi Li*, Wei Li, Tao Liu, Tianjian Li, Hengshuang Zhao# (* equal contribution, # corresponding author)
International Conference on Learning Representations (ICLR) 2026
A full training recipe to reproduce OpenAI o3-style thinking-with-images capability.
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Xin Lai*, Junyi Li*, Wei Li, Tao Liu, Tianjian Li, Hengshuang Zhao# (* equal contribution, # corresponding author)
International Conference on Learning Representations (ICLR) 2026
A full training recipe to reproduce OpenAI o3-style thinking-with-images capability.
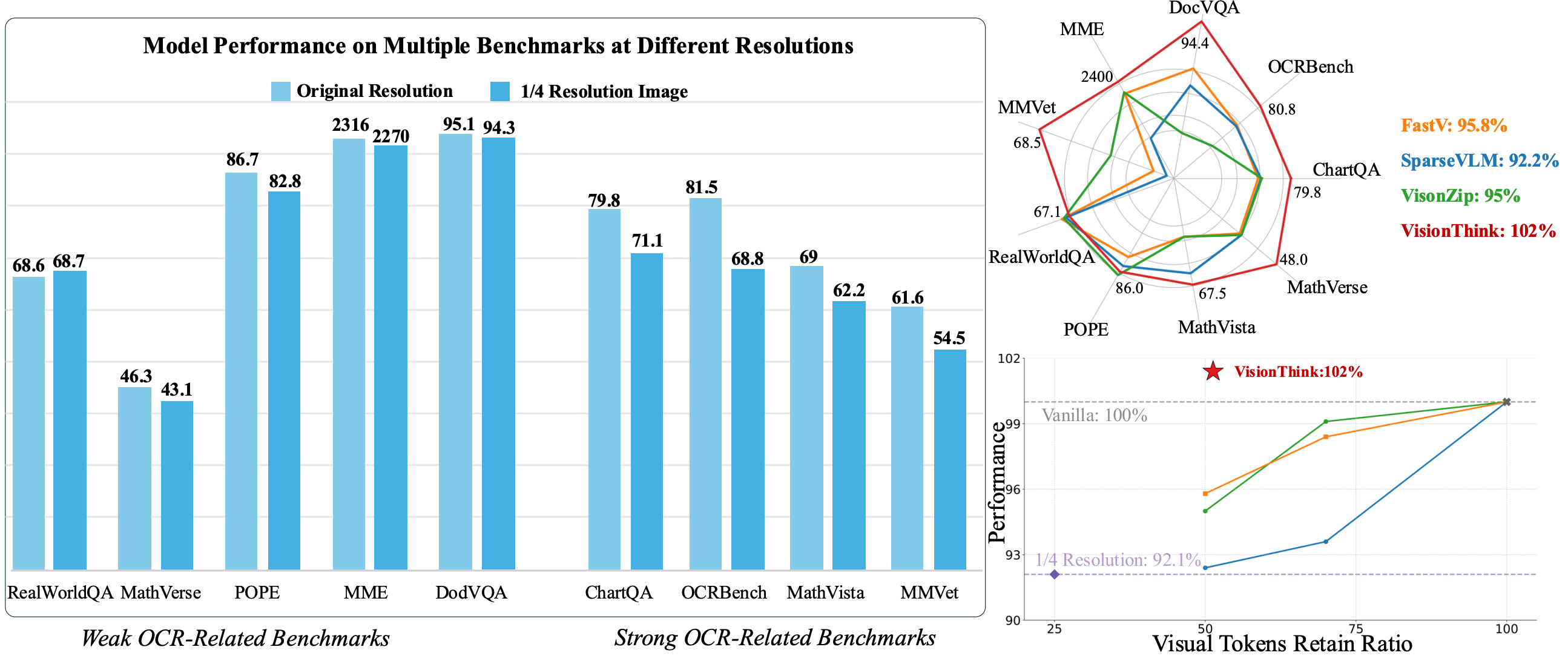
VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
Senqiao Yang*, Junyi Li*, Xin Lai*, Bei Yu, Hengshuang Zhao, Jiaya Jia (* equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2025 Poster
A new paradigm of efficient VLMs with token compression.
VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
Senqiao Yang*, Junyi Li*, Xin Lai*, Bei Yu, Hengshuang Zhao, Jiaya Jia (* equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2025 Poster
A new paradigm of efficient VLMs with token compression.
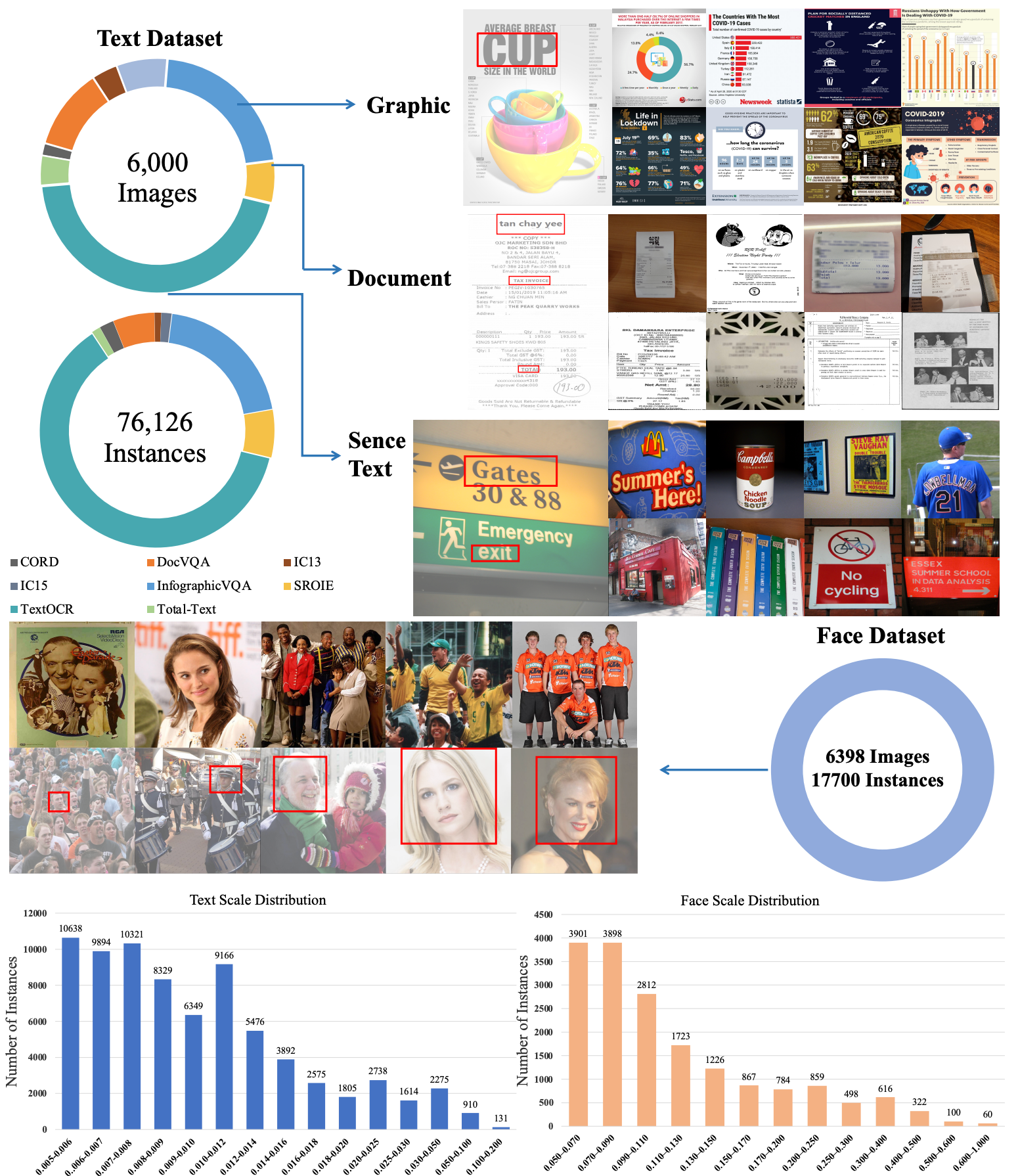
TokBench: Evaluating Your Visual Tokenizer before Visual Generation
Junfeng Wu*, Dongliang Luo*, Weizhi Zhao, Zhihao Xie, Yuanhao Wang, Junyi Li, Xudong Xie, Yuliang Liu, Xiang Bai# (* equal contribution, # corresponding author)
Under review. 2025
A simple Benchmark for evaluating your visual tokenizer.
TokBench: Evaluating Your Visual Tokenizer before Visual Generation
Junfeng Wu*, Dongliang Luo*, Weizhi Zhao, Zhihao Xie, Yuanhao Wang, Junyi Li, Xudong Xie, Yuliang Liu, Xiang Bai# (* equal contribution, # corresponding author)
Under review. 2025
A simple Benchmark for evaluating your visual tokenizer.
2024
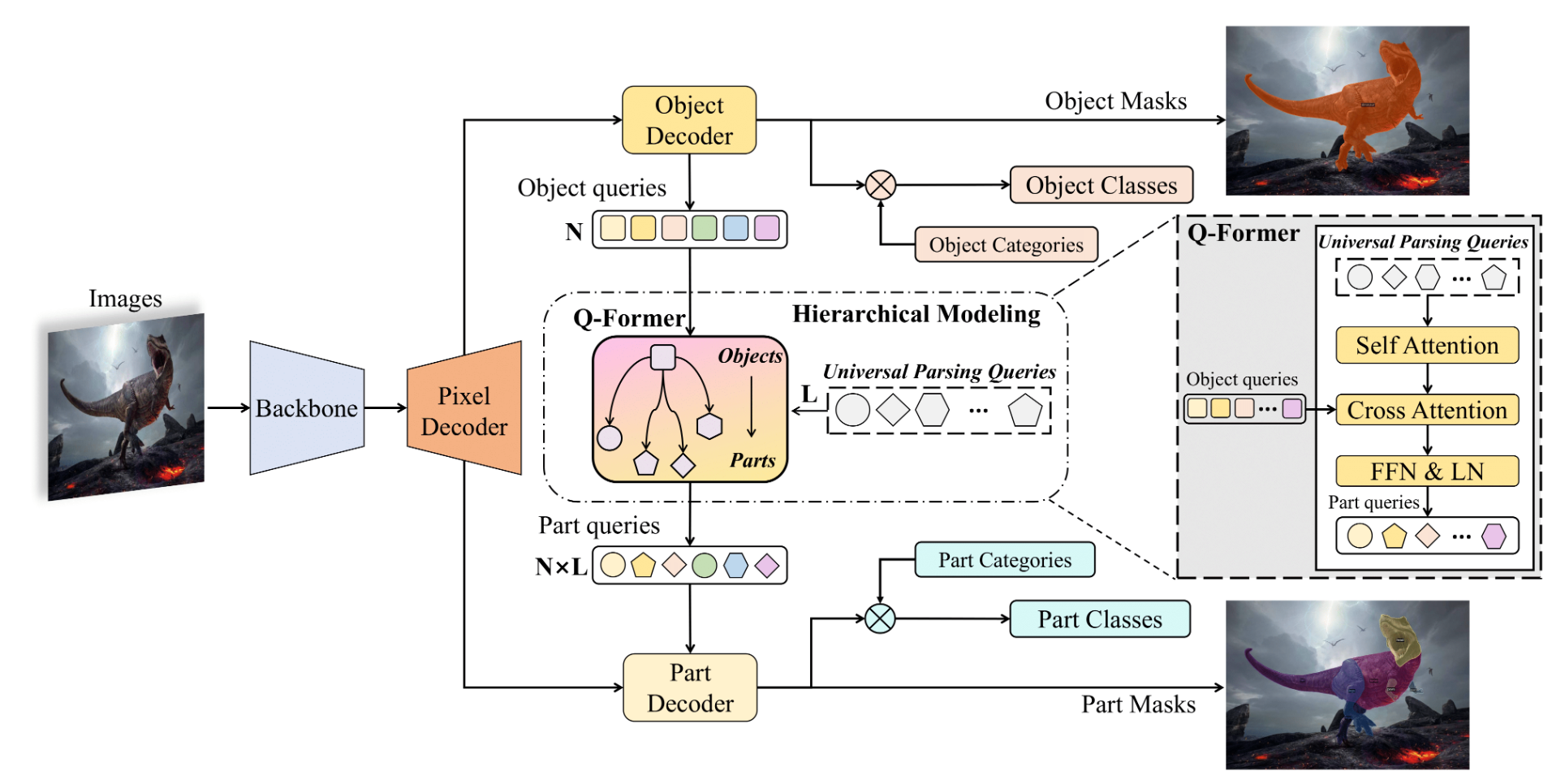
PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects
Junyi Li*, Junfeng Wu*, Weizhi Zhao, Song Bai, Xiang Bai# (* equal contribution, # corresponding author)
Eurepean Conference on Computer Vision (ECCV) 2024 Poster
The first part-level foundation model for locating and identifying both objects and parts in images through a hierarchical framework.
PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects
Junyi Li*, Junfeng Wu*, Weizhi Zhao, Song Bai, Xiang Bai# (* equal contribution, # corresponding author)
Eurepean Conference on Computer Vision (ECCV) 2024 Poster
The first part-level foundation model for locating and identifying both objects and parts in images through a hierarchical framework.